En esta entrada vamos a intentar exponer uno de los grandes problemas de la robótica móvil. Tal y como hemos visto hasta ahora, para que un robot navegue necesita tener un mapa del entorno. Más concretamente, para poder localizarse, un robot necesita un mapa del entorno. Hasta ahora, siempre hemos esquivado esta pregunta, pero seguro que muchos de vosotros ya habéis pensado en más de una ocasión: ¿cómo puede un robot obtener un mapa de su entorno? Intuitivamente, un robot puede ir recorriendo sus alrededores e ir grabando la información que recopilan sus sensores. Pero claro, para poder tener un mapa bien hecho, se necesita saber dónde se han obtenido los datos de los sensores. Es decir, para hacer un mapa, un robot debe saber localizarse. Pero para localizarse, necesita un mapa. A todas luces ¡estamos ante el problema del huevo y la gallina!
Matemáticamente, esto es muy fácil de ver. Ya hemos visto que para localización, se ha de resolver el problema de , es decir, obtener la distribución probabilística de la posición (), sabiendo los datos de los sensores (), los movimientos ejectuados por el robot () y el mapa (). De la misma forma, el problema del mapeo es calcular . Además de los datos de los sensores y los movimientos ejecutados, necesitamos saber la posición del robot en cada instante. Como véis, tenemos una dependencia cíclica entre posición y mapa. Una forma de romper esta dependencia sería tener un sistema de posicionamiento externo, independiente del robot. Estamos hablando de algo semejante a un GPS. Pero esto ya implica tener infraestructura externa al robot. En el caso del GPS serían los 24 satélites que orbitan nuestro planeta. Además, el GPS comercial, el que tenemos en nuestros coches y móviles, no da la precisión necesaria para poder mapear fielmente. Su precisión en la posición es del orden de metros. Más pegas del GPS: no funcionan en interiores, por lo que nos podemos olvidar de mapear entornos como casas, talleres, almacenes, hospitales y un largo etcétera. Por estas razones, nosotros queremos resolver el problema sin recurrir a infraestructuras externas. Lo tenemos que resolver con lo que ya tenemos en el robot.
Lo primero que se le ocurre a uno es tirar de odometría. ¡Eso es! La odometría nos da una estimación de la posición del robot. Aunque tenemos que recordar que hasta ahora nunca nos hemos fiado de la odometría. Pero bueno, ¿por qué no probarlo? El resultado de mapear usando la odometría como única estimación de la posición se puede ver en la siguiente imagen:
Figura 1: a la izquierda, el resultado de un proceso de mapeo que utiliza la odometría como estimación de posición; a la derecha, el mapa real del entorno
Obviamente, el resultado deja mucho que desear. Y no nos extraña, ya que en su día lo vimos en la entrada sobre odometría. Entonces argumentamos por qué la odometría no es una buena fuente de estimación de posición. Ahora, con la Figura 1, lo hemos confirmado totalmente, ¿verdad? Visto lo visto, la única solución es afrontar la realidad. Necesitamos diseñar un proceso que no sólo mapée un entorno, sino que a la vez se localice. Matemáticamente, necesitamos calcular la distribución de probabilidad de . ¡Casi nada! Tenemos que estimar la posición y el mapa simultaneamente, sabiendo los datos de los sensores y los movimientos ejecutados por el robot.
SLAM
SLAM, del inglés Simultaneous Localization and Mapping (mapear y localizar simultaneamente), es el nombre que se le da al problema que queremos resolver. Ha sido un problema muy estudiado, que todavía hoy mismo sigue en la vanguardia de la investigación, con múltiples aplicaciones y ramificaciones. Sería imposible poder abarcar toda la literatura que hay sobre el tema, por lo que aquí nos vamos a conformar con ver las ideas clave. La intención de esta entrada es que se entienda el problema del SLAM, captar su dificultad y hacernos con una idea de qué técnicas se utilizan para poder resolverlo.
Lo primero que tenemos que entender es qué es un mapa. Para el problema del SLAM, con el objetivo de facilitar la comprensión del mismo, hablaremos de mapas de características. Una característica puede ser una esquina, una pared, una puerta… es decir, alguna propiedad característica de un entorno que se pueda reconocer. Así pues, para nosotros, un mapa será un conjunto de características con sus coordenadas espaciales: dónde es el número de características de nuestro mapa. Por otro lado, también tenemos que estimar la posición del robot, , por lo que agrupando mapa y posición, tenemos que calcular una distribución de probabilidades para un espacio de dimensiones. Teniendo en cuenta que un mapa típico facilimente puede superar el orden de las decenas de miles de características, estamos hablando de espacios de ¡más de 10 mil dimensiones! Esto, a bote pronto, nos da una idea de la dificultad del problema. Por suerte, en el mundo hay grandes investigadores que no se han amedrentado con la magnitud de este problema y han propuesto soluciones. Nosotros vamos a describir una de esas soluciones, intentando dar una descripción intuitiva del proceso que se sigue. Para aquellos que quieran profundizar más en el tema, la solución que vamos a ver aquí es el llamado GRAPH SLAM, dónde graph significa, como no, grafo.
GRAPH SLAM
Utilizando ejemplos muy sencillos, primero vamos a describir el proceso o algoritmo del GraphSLAM. Como veréis, el proceso es sorprendentemente sencillo, pero los fundamentos matématicos que lo sustentan son bastante profundos. Imaginemos que nuestro robot se encuentra en la posición . Por ahora, con la intención de simplificar el problema, no consideraremos la orientación del robot. El robot ejecuta un movimiento. Pongamos que ha avanzado 0.5 metros. En un mundo ideal, sabríamos que la nueva posición del robot sería y , ya que el movimiento sólo se ha dado en . Pero ya hemos leído muchas entradas de robótica como para saber que la incertidumbre nos acecha en cada una de nuestras mediciones. Es por ello que sabemos que la nueva posición del robot se puede ver como una gaussiana que se centra en .
Figura 2: Movimiento del robot en el eje x y su incertidumbre
El movimiento de la Figura 2 se puede visualizar como un grafo de dos nodos y un arco. Los nodos serían las dos posiciones y el arco sería la gaussiana que une ambos nodos. Algo así:
Figura 3: Grafo de movimiento con dos nodos representando las posiciones y el arco representando el ruido gaussiano del movimiento
En el grafo de la Figura 3 no hemos hecho más que poner las dos posiciones que se unen con el movimiento, que es el que introduce la incertidumbre en forma de una gaussiana centrada en . Recordad que es la varianza. A medida que la varianza sea más pequeña, más seguros estaremos de nuestra posición, o dicho de otra forma, la incertidumbre en la posición introducida por el movimiento será menor.
A lo largo de su recorrido, nuestro robot va extrayendo características de su entorno, utilizando los sensores que tiene. Para simplificar nuestra explicación, supondremos que estamos en un mundo uni-dimensional, dónde las posiciones del robot son y las características observadas son . Lo que medimos de las características es la distancia a las que el robot las observa. Tened en cuenta, una vez más, que estas distancias también son inciertas. En el proceso de medida tenemos incertidumbre. Como de costumbre modelaremos esa incertidumbre mediante una gaussiana (increíble lo bueno que nos ha salido el tal Gauss 😉 ).
Vamos a por un ejemplo sencillo que combina movimientos y observaciones de características. Pongamos que nuestro robot se ha movido de a y luego a . Pongamos también, que en ha observado la característica , en ha observado y , para finalmente observar desde . Esta situación queda descrita por el siguiente grafo:
Figura 4: Grafo de movimientos y observaciones
Para aplicar el proceso de GraphSLAM en este simple ejemplo, primero tenemos que presentar las herramientas que vamos a utilizar. Por un lado tenemos una matriz cuadrada que representa la relación entre los distintos nodos del grafo. Por tanto, esta matriz va a ser de 5 x 5 en este caso, ya que tenemos tres posiciones y dos caraterísticas. A la matriz en cuestión se la conoce como matriz de información y se le asigna la letra griega . Os presentamos a :
Acompañando a esta solitaria matriz, tenemos el llamado vector de información, que guarda información relativa a los movimientos y observaciones hechas en el grafo de la Figura 4. Este vector tiene 5 elementos. Para que parezca que estamos haciendo cosas muy serias, le asignamos la letra griega 😉
Al comienzo del proceso, todos los valores de y se inicializan con el valor 0. A partir de ahora solo tenemos que aprender cómo incoporar la información de la Figura 4 a la matriz y el vector de información. El proceso se completa en tres pasos:
Incorporar la información relativa a la posición inicial del robot
Incorporar los movimientos ejecutados por el robot
Incorporar la información relativa a las observaciones realizadas por el robot en la posición correspondiente
Vamos a ver cada uno de los pasos. Empezamos con el primer paso. La posición inicial del robot es la única referencia que tenemos del marco global de referencia. A partir de esa posición inicial, todos los movimientos son relativos. En este ejemplo consideraremos que la posición inicial del robot es el origen, es decir, . Para incorporar esta información en la matriz, tenemos que sumar un 1 en la celda y un 0 en el primer elemento del vector. Nos quedaría así:
Ahora nos ocuparemos del primer movimiento entre y . Según la Figura 4, . Reescribiremos esta ecuación de otra forma, con el objetivo de facilitar su incorporación a la matriz y el vector de información: . Esta expresión nos servirá para rellenar la primera fila. En la celda sumaremos un 1 (el multiplicador de en la expresión), en la celda sumaremos un -1 (el multiplicador de en la expresión), y finalmente sumaremos un -7 en el primer elemento del vector.
Pero este movimiento también nos hace actualizar la segunda fila. Reescribiendo la ecuación anterior como , vamos a actualizar las celdas , y el segundo elemento del vector. Los valores a sumar serán -1, 1 y 7 respectivamente. Después de este primer movimiento, la matriz y el vector quedarían de esta forma:
Ya hemos incorporado la posición inicial y el primer movimiento. Como habéis visto, solo se trata de sumar valores en las celdas adecuadas, sin mayor dificultad. Al tratarse de sumas, el orden en que vayamos incorporándolas no tiene ninguna importancia. Así que antes de sumar los demás movimientos, veremos cómo sumar una observación. Vayamos con la observación de la característica desde la posición . La Figura 4 nos indica que la característica ha sido observada a 10 unidades desde la posición , por lo que . Vamos a reescribir la ecuación: . De forma similar a los movimientos, esta obsercación hará que actualicemos las celdas y , así como el primer elemento del vector. Reescribiendo la ecuación como , nos damos cuenta que también tenemos que actualizar las celdas , y el cuarto elemento del vector. Los valores a actualizar son faciles de extrarer de las dos expresiones que acabamos de ver. Una vez hechas las sumas, así nos quedarían la matriz y el vector:
¡Esto ya está cogiendo forma! Ahora que sabemos incorporar movimientos y observaciones, os dejo que cojáis papel y lápiz y terminéis con lo que queda. Si todo va bien, os debería salir lo siguiente:
Fijaos que en la matriz hay mucha información sobre el proceso de mapeo. Por ejemplo, si vamos a la línea de la matriz, podemos leer que la característica ha sido observada 2 veces, información que se obtiene mirando la celda . Además, sabemos también que ha sido observada desde la posición y (mirad las celdas y . Mirando la matriz también sabemos que la posición más activa ha sido , con 4 acciones. Ha habido 2 movimientos y dos observaciones.
Todo esto está muy bien, pero ¿qué hacemos ahora con esta matriz y este vector? Por muy sorprendente que parezca, nos será suficiente con calcular la inversa de la matriz y multiplicarla por el vector para tener el resultado perseguido: las posiciones del robot y las características observadas.
En este caso, es la mejor estimación del vector . Si lo probáis veréis que para nuestro caso . No está nada mal, ¿verdad? Lo que viene a decir es que las posiciones absolutas del robot durante su recorrido son 0, 7 y 12. Pero también nos dice que la característica está a 10 unidades de distancia del origen y a 13. Es decir, contiene la información que queríamos del mapa y la trayectoria del robot.
De todas formas, alguno ya estará pensando en que lo que hemos hecho no es muy espectacular. Cogiendo el grafo de la Figura 4 los valores de eran muy obvios. Así es, ya que hemos puesto datos perfectos sin ninguna incertidumbre. Y ese no es el caso real…
Introduciendo la incertidumbre
Vamos a intentar hilar más fino y simular mejor los datos que tendríamos con un robot real. Imaginemos que nuestro robot tiene una odometría poco de fiar, como de costumbre. Pero en este caso, la odometría tiende a medir menos distancia que la que el robot realmente ha recorrido. Actualizamos el grafo de la Figura 4 y tenemos lo siguiente:
Figura 5: grafo de la Figura 4 con mediciones incorrectas de odometría
Como véis, no hemos tocado las observaciones, ya que nos fiamos mucho de los resultados de la extracción de características. En este caso, con la odometría defectuosa, vemos que el grafo no es consistente como antes. Por ejemplo, la característica ha sido observada a 10 unidades de distancia en la posición . Después, el robot se ha desplazado 6 unidades según la odometría, y ha observado a 3 unidades. ¿A qué distancia del punto 0 se encuentra ? ¿A 10 o a 9? Esto es lo que pasa cuando nuestros sensores se enfrentan al mundo real.
Para enfrentarnos a esta situación necesitamos recurrir de nuevo a los modelos probabilísticos del movimiento y de la observación. Ya hemos dicho antes que vamos a modelar ambos procesos con gaussianas. Por lo tanto, es suficiente con saber la desviación típica para la gaussiana del movimiento y para la gaussiana de la observación. Digamos que es la desviación típica para el movimiento, mientras que es para la observación. Estos valores nos indican que la incertidumbre en la observación es 5 veces menor que la del movimiento. Nos fiamos mucho más de las observaciones que de los movimientos.
Pero ¿cómo acomodamos esta nueva información en la matriz y en el vector de información? Es mucho más sencillo de lo que pensáis. Lo único que hay que hacer es multiplicar por todas aquellas expresiones de movimiento y por todas las expresiones de observación. Así, el primer movimiento entre y , pasaría de ser a:
Las expresiones para las observaciones se transforman de igual manera, solo que multiplicamos por . Después de estas transformaciones sencillas, tenemos que seguir el proceso de antes, incorporando los coeficientes a la matriz y al vector. Igual-igual que antes. Si todo lo hemos hecho bien, nos debe haber quedado lo siguiente:
Ahora es cuando llega la magia. Cuando calculamos invirtiendo la matriz y mutliplicándola por el vector , obtenemos que:
¿No os parece increíble? La posición ha pasado de 6 a 6.7143 mientras que ha pasado de 6+4=10 a 11.7143. Las posiciones de las características observadas también se han ajustado, aunque menos que las posiciones. Algo esperable, ya que la incertidumbre de las observaciones era menor, lo que hace que el mapeo se base más en lo observado.
¿Dónde está el truco?
Aquí no hay nada de magia, sino que matemáticas. Lo que habéis presenciado es el funcionamiento del llamado filtro de información. Dicho muy por encima, el filtro de información es un algoritmo recursivo de estimación de variables, muy del estilo del conocido filtro de Kalman. De hecho ambos algoritmos comparten familia dentro de los llamados filtros Gaussianos. El objetivo del filtro de información es estimar variables aleatorias que no podemos medir directamente, usando información de otras variables que sí podemos medir. En nuestro caso, el objetivo era obtener la trayectoria del robot y el mapa del entorno, sabiendo las observaciones hechas por el robot y las posiciones medidas por odometría.
Lo que distingue a los filtros Gaussianos es que en ellos se asume que la distribución probabilística de las variables es Gaussiana. Es decir, en el caso del GraphSLAM, hemos asumido que la distribución de la trayectoria y del mapa viene dada por una Gaussiana de muchas dimensiones (en nuestro ejemplo 5). Y usando el filtro de información hemos encontrado la media de esa Gaussiana: . Seguramente muchos de vosotros sabéis que la media de una Gaussiana es el punto en el que la campana adquiere mayor altura. La lectura para nosotros es que representa la estimación más probable para la trayectoria y el mapa.
Pero todavía no se ve muy claro cómo se relacionan las Gaussianas con nuestra matriz y nuestro vector de información. Vamos a intentar daros unas pistas. Empecemos por hablar de la famosa campana de Gauss y su representación paramétrica.
Figura 6: campana de Gauss
La campana de Gauss de la Figura 6 es una función de distribución de probabilidad. Como véis en la imagen, se suele representar con dos parámetros: y . El primer valor es el que divide la campana en dos partes simétricas y se conoce como media. El segundo valor, conocido como desviación estándar, nos da una medida de la anchura de la campana. Es muy intuitivo. A valores más pequeños de , tendremos campanas más estrechas y altas. Eso significa que la mayoría de valores de nuestra campana se encuentran cerca de la media. Sin embargo, para desviaciones estándar grandes, la campana se hace más ancha y más baja. Los valores se alejan de la media. Para nosotros, la media representa el valor más probable y la desviación estándar nos da la seguridad sobre nuestra estimación. Una desviación estándar pequeña nos hace estar seguros.
De esta forma podemos parametrizar una Gaussiana para una dimensión. Generalizando a cualquier número de dimensiones, se convierte en un vector de tantas dimensiones como nuestras variables. La desviación estándar, se convierte en la llamada matriz de covarianza: . Sus dimensiones son dim() x dim(). En el ejemplo que hemos visto en esta entrada, la matriz de covarianza tendría 5 líneas y 5 columnas. Resumiendo, una Gaussiana para dimensiones arbitrarias, se puede representar usando los parámetros y .
Da la casulidad que para representar una Gaussiana podemos usar otra parametrización: la llamada parametrización canónica. Esta nueva representación utiliza a nuestros amigos y . ¿A qué no os lo esperabais? La matriz es la inversa de la matriz de covarianza: . Por otro lado, el vector se define cómo: . ¿A qué ahora empezáis a intuir por donde van los tiros? Bien, ¡rematémoslo!
Ahora entendemos que la matriz y el vector de información que hemos estado construyendo en el ejemplo anterior nos servían para representar una Gaussiana en el espacio de la trayectoria y el mapa. Pero, ¿cómo encajan los números que hemos ido sumando?
En el último ejemplo de la Figura 5 el robot hacía un movimiento entre y , desplazándose 6 unidades. Decíamos que la incertidumbre en el movimiento era de . Con la expresión matemática de una Gaussiana entre manos, el movimiento se describe así:
El segundo movimiento también se describe con una expresión casi idéntica. Ahora bien, ¿cuál es la probabilidad total de ambos movimientos? Ni más ni menos que el producto de las dos gaussianas anteriormente citadas:
x
Es este producto el que nos interesa maximizar para obtener los valores más probables de , y . Y para maximizar algo así, tenemos algunos trucos matemáticos que nos facilitarán la vida. Por un lado, podemos borrar la constante , ya que es igual para todos. Nos quedamos solo con las exponenciales. Ahora viene lo bonito, ya que multiplicando nuestros exponenciales por logaritmos, conseguiremos que el producto de exponenciales se convierta en una suma mucho más simple de manejar. Tened en cuenta que computacionalmente las sumas son menos costosas de calcular que los productos, por lo que siempre tendemos a buscar sumas. Con este último truco, nos quedamos con:
Una vez más, mandamos a la constante a paseo. Y por último, nos deshacemos de las potencias de dos. Así, lo que tenemos que maximizar se queda en:
+
¡Estas expresiones se parecen sospechosamnete a las expresiones que íbamos sumando en la matriz y el vector ! Al fin y al cabo, lo que estábamos haciendo durante ese proceso era incorporar la información determinante de unas gaussianas que describían procesos de movimiento y observación de características. Lo hacíamos sumando, ya que para calcular la probabilidad total habíamos convertido el producto de gaussianas en sumas más simples.
Así es como funciona intuitivamente un filtro de información, la base del GraphSLAM. Así es cómo podemos obtener mapas de entornos totalmente desconocidos. Con técnicas similares a las descritas en esta entrada y con muchísimo trabajo más en temas tan importantes como extracción de características y asociación de datos, se pueden hacer cosas tan increíbles como estas:
En el siguiente video tenéis un bonito ejemplo de SLAM con el famoso y barato sensor Kinect:
Con esta entrada damos por concluido el mini-curso de navegación autónoma. A lo largo del mismo hemos aprendido cosas muy interesantes como planificar trayectorias, evitar obstáculos, localizarse usando mapas de entornos y cómo obtener mapas de un entorno desconocido. Espero haber transmitido las ideas básicas de la navegación autónoma, que también nos servirán en otros ámbitos de la robótica, dónde los problemas suelen ser parecidos.
En las entradas correspondientes al minicurso: Universo inflacionario hemos empezado a discutir los diferentes modelos inflacionarios. En estas discusiones sobre estos modelos vamos a hablar muchas veces sobre el concepto de falso vacío.
En esta entrada vamos a intentar explicar este concepto, su significado y sus propiedades. Esperamos que con esto se pueda seguir el minicurso mencionado con mayor facilidad.
Una vez leídas estas entradas vamos a intentar explicar en esta cómo la inflación propone soluciones a los mencionados problemas. La explicación será conceptual.
Premiado en el IV Concurso de Divulgación Científica del Centro Nacional de Física de Partículas, Astropartículas y Nuclear (CPAN) Proyecto Consolider-Ingenio 2010
La entrada sobre femtoquímica ha sido reconocida con el Premio ED a la excelencia en la divulgación científica.

 Continuamos con la serie Cuántica y Garabatos sobre los diagramas de Feynman.
Continuamos con la serie Cuántica y Garabatos sobre los diagramas de Feynman.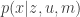 , es decir, obtener la distribución probabilística de la posición (
, es decir, obtener la distribución probabilística de la posición ( ), sabiendo los datos de los sensores (
), sabiendo los datos de los sensores ( ), los movimientos ejectuados por el robot (
), los movimientos ejectuados por el robot ( ) y el mapa (
) y el mapa ( ). De la misma forma, el problema del mapeo es calcular
). De la misma forma, el problema del mapeo es calcular 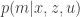 . Además de los datos de los sensores y los movimientos ejecutados, necesitamos saber la posición del robot en cada instante. Como véis, tenemos una dependencia cíclica entre posición y mapa. Una forma de romper esta dependencia sería tener un sistema de posicionamiento externo, independiente del robot. Estamos hablando de algo semejante a un GPS. Pero esto ya implica tener infraestructura externa al robot. En el caso del GPS serían los 24 satélites que orbitan nuestro planeta. Además, el GPS comercial, el que tenemos en nuestros coches y móviles, no da la precisión necesaria para poder mapear fielmente. Su precisión en la posición es del orden de metros. Más pegas del GPS: no funcionan en interiores, por lo que nos podemos olvidar de mapear entornos como casas, talleres, almacenes, hospitales y un largo etcétera. Por estas razones, nosotros queremos resolver el problema sin recurrir a infraestructuras externas. Lo tenemos que resolver con lo que ya tenemos en el robot.
. Además de los datos de los sensores y los movimientos ejecutados, necesitamos saber la posición del robot en cada instante. Como véis, tenemos una dependencia cíclica entre posición y mapa. Una forma de romper esta dependencia sería tener un sistema de posicionamiento externo, independiente del robot. Estamos hablando de algo semejante a un GPS. Pero esto ya implica tener infraestructura externa al robot. En el caso del GPS serían los 24 satélites que orbitan nuestro planeta. Además, el GPS comercial, el que tenemos en nuestros coches y móviles, no da la precisión necesaria para poder mapear fielmente. Su precisión en la posición es del orden de metros. Más pegas del GPS: no funcionan en interiores, por lo que nos podemos olvidar de mapear entornos como casas, talleres, almacenes, hospitales y un largo etcétera. Por estas razones, nosotros queremos resolver el problema sin recurrir a infraestructuras externas. Lo tenemos que resolver con lo que ya tenemos en el robot.
 . ¡Casi nada! Tenemos que estimar la posición y el mapa simultaneamente, sabiendo los datos de los sensores y los movimientos ejecutados por el robot.
. ¡Casi nada! Tenemos que estimar la posición y el mapa simultaneamente, sabiendo los datos de los sensores y los movimientos ejecutados por el robot. dónde
dónde  es el número de características de nuestro mapa. Por otro lado, también tenemos que estimar la posición del robot,
es el número de características de nuestro mapa. Por otro lado, también tenemos que estimar la posición del robot, 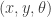 , por lo que agrupando mapa y posición, tenemos que calcular una distribución de probabilidades para un espacio de
, por lo que agrupando mapa y posición, tenemos que calcular una distribución de probabilidades para un espacio de 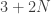 dimensiones. Teniendo en cuenta que un mapa típico facilimente puede superar el orden de las decenas de miles de características, estamos hablando de espacios de ¡más de 10 mil dimensiones! Esto, a bote pronto, nos da una idea de la dificultad del problema. Por suerte, en el mundo hay grandes investigadores que no se han amedrentado con la magnitud de este problema y han propuesto soluciones. Nosotros vamos a describir una de esas soluciones, intentando dar una descripción intuitiva del proceso que se sigue. Para aquellos que quieran profundizar más en el tema, la solución que vamos a ver aquí es el llamado GRAPH SLAM, dónde graph significa, como no, grafo.
dimensiones. Teniendo en cuenta que un mapa típico facilimente puede superar el orden de las decenas de miles de características, estamos hablando de espacios de ¡más de 10 mil dimensiones! Esto, a bote pronto, nos da una idea de la dificultad del problema. Por suerte, en el mundo hay grandes investigadores que no se han amedrentado con la magnitud de este problema y han propuesto soluciones. Nosotros vamos a describir una de esas soluciones, intentando dar una descripción intuitiva del proceso que se sigue. Para aquellos que quieran profundizar más en el tema, la solución que vamos a ver aquí es el llamado GRAPH SLAM, dónde graph significa, como no, grafo. . Por ahora, con la intención de simplificar el problema, no consideraremos la orientación del robot. El robot ejecuta un movimiento. Pongamos que ha avanzado 0.5 metros. En un mundo ideal, sabríamos que la nueva posición del robot sería
. Por ahora, con la intención de simplificar el problema, no consideraremos la orientación del robot. El robot ejecuta un movimiento. Pongamos que ha avanzado 0.5 metros. En un mundo ideal, sabríamos que la nueva posición del robot sería  y
y 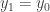 , ya que el movimiento sólo se ha dado en
, ya que el movimiento sólo se ha dado en 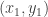 .
.

 es la varianza. A medida que la varianza sea más pequeña, más seguros estaremos de nuestra posición, o dicho de otra forma, la incertidumbre en la posición introducida por el movimiento será menor.
es la varianza. A medida que la varianza sea más pequeña, más seguros estaremos de nuestra posición, o dicho de otra forma, la incertidumbre en la posición introducida por el movimiento será menor.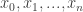 y las características observadas son
y las características observadas son 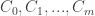 . Lo que medimos de las características es la distancia a las que el robot las observa. Tened en cuenta, una vez más, que estas distancias también son inciertas. En el proceso de medida tenemos incertidumbre. Como de costumbre modelaremos esa incertidumbre mediante una gaussiana (increíble lo bueno que nos ha salido el tal Gauss 😉 ).
. Lo que medimos de las características es la distancia a las que el robot las observa. Tened en cuenta, una vez más, que estas distancias también son inciertas. En el proceso de medida tenemos incertidumbre. Como de costumbre modelaremos esa incertidumbre mediante una gaussiana (increíble lo bueno que nos ha salido el tal Gauss 😉 ). a
a  y luego a
y luego a  . Pongamos también, que en
. Pongamos también, que en 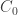 , en
, en  , para finalmente observar
, para finalmente observar 
 . Os presentamos a
. Os presentamos a 
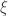 😉
😉
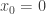 . Para incorporar esta información en la matriz, tenemos que sumar un 1 en la celda
. Para incorporar esta información en la matriz, tenemos que sumar un 1 en la celda  y un 0 en el primer elemento del vector. Nos quedaría así:
y un 0 en el primer elemento del vector. Nos quedaría así:
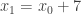 . Reescribiremos esta ecuación de otra forma, con el objetivo de facilitar su incorporación a la matriz y el vector de información:
. Reescribiremos esta ecuación de otra forma, con el objetivo de facilitar su incorporación a la matriz y el vector de información:  . Esta expresión nos servirá para rellenar la primera fila. En la celda
. Esta expresión nos servirá para rellenar la primera fila. En la celda 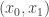 sumaremos un -1 (el multiplicador de
sumaremos un -1 (el multiplicador de  , vamos a actualizar las celdas
, vamos a actualizar las celdas  ,
, 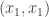 y el segundo elemento del vector. Los valores a sumar serán -1, 1 y 7 respectivamente. Después de este primer movimiento, la matriz y el vector quedarían de esta forma:
y el segundo elemento del vector. Los valores a sumar serán -1, 1 y 7 respectivamente. Después de este primer movimiento, la matriz y el vector quedarían de esta forma:
 . Vamos a reescribir la ecuación:
. Vamos a reescribir la ecuación:  . De forma similar a los movimientos, esta obsercación hará que actualicemos las celdas
. De forma similar a los movimientos, esta obsercación hará que actualicemos las celdas 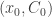 , así como el primer elemento del vector. Reescribiendo la ecuación como
, así como el primer elemento del vector. Reescribiendo la ecuación como  , nos damos cuenta que también tenemos que actualizar las celdas
, nos damos cuenta que también tenemos que actualizar las celdas  ,
,  y el cuarto elemento del vector. Los valores a actualizar son faciles de extrarer de las dos expresiones que acabamos de ver. Una vez hechas las sumas, así nos quedarían la matriz y el vector:
y el cuarto elemento del vector. Los valores a actualizar son faciles de extrarer de las dos expresiones que acabamos de ver. Una vez hechas las sumas, así nos quedarían la matriz y el vector:

 . Mirando la matriz también sabemos que la posición más activa ha sido
. Mirando la matriz también sabemos que la posición más activa ha sido 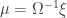
 es la mejor estimación del vector
es la mejor estimación del vector  . Si lo probáis veréis que para nuestro caso
. Si lo probáis veréis que para nuestro caso  . No está nada mal, ¿verdad? Lo que viene a decir
. No está nada mal, ¿verdad? Lo que viene a decir 
 para la gaussiana del movimiento y para la gaussiana de la observación. Digamos que
para la gaussiana del movimiento y para la gaussiana de la observación. Digamos que  es la desviación típica para el movimiento, mientras que
es la desviación típica para el movimiento, mientras que 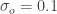 es para la observación. Estos valores nos indican que la incertidumbre en la observación es 5 veces menor que la del movimiento. Nos fiamos mucho más de las observaciones que de los movimientos.
es para la observación. Estos valores nos indican que la incertidumbre en la observación es 5 veces menor que la del movimiento. Nos fiamos mucho más de las observaciones que de los movimientos.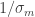 todas aquellas expresiones de movimiento y por
todas aquellas expresiones de movimiento y por 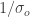 todas las expresiones de observación. Así, el primer movimiento entre
todas las expresiones de observación. Así, el primer movimiento entre  a:
a: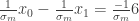

 y mutliplicándola por el vector
y mutliplicándola por el vector  , obtenemos que:
, obtenemos que:
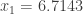

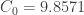
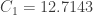

 . Sus dimensiones son dim(
. Sus dimensiones son dim( . Por otro lado, el vector
. Por otro lado, el vector  . ¿A qué ahora empezáis a intuir por donde van los tiros? Bien, ¡rematémoslo!
. ¿A qué ahora empezáis a intuir por donde van los tiros? Bien, ¡rematémoslo!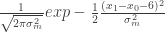
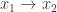 también se describe con una expresión casi idéntica. Ahora bien, ¿cuál es la probabilidad total de ambos movimientos? Ni más ni menos que el producto de las dos gaussianas anteriormente citadas:
también se describe con una expresión casi idéntica. Ahora bien, ¿cuál es la probabilidad total de ambos movimientos? Ni más ni menos que el producto de las dos gaussianas anteriormente citadas:
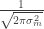 , ya que es igual para todos. Nos quedamos solo con las exponenciales. Ahora viene lo bonito, ya que multiplicando nuestros exponenciales por logaritmos, conseguiremos que el producto de exponenciales se convierta en una suma mucho más simple de manejar. Tened en cuenta que computacionalmente las sumas son menos costosas de calcular que los productos, por lo que siempre tendemos a buscar sumas. Con este último truco, nos quedamos con:
, ya que es igual para todos. Nos quedamos solo con las exponenciales. Ahora viene lo bonito, ya que multiplicando nuestros exponenciales por logaritmos, conseguiremos que el producto de exponenciales se convierta en una suma mucho más simple de manejar. Tened en cuenta que computacionalmente las sumas son menos costosas de calcular que los productos, por lo que siempre tendemos a buscar sumas. Con este último truco, nos quedamos con:
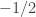 a paseo. Y por último, nos deshacemos de las potencias de dos. Así, lo que tenemos que maximizar se queda en:
a paseo. Y por último, nos deshacemos de las potencias de dos. Así, lo que tenemos que maximizar se queda en:





